在迁移到这里之前,洒家使用了 3 年博客园平台(链接)。个人认为博客园、CSDN 这种博客网站有很多缺点,例如不能真正掌握自己的数据,不方便定制,环境和氛围不好。此外,还经常有各种爬虫网站不加署名地转载我的文章(感谢百度,盗版排名高于正版)。2017 年 4 月,洒家终于忙中偷闲,改用 Pelican 静态网站生成器,把博客独立出来,迁移到了 GitHub Pages。希望这个博客可以见证一只菜鸟小白的成长。
这篇文章主要讨论我自己搭建博客的一些经验和细节,不讨论关于 Python、pip、pyenv、virtualenv、git、shell script、make、Markdown 的基础知识,也不讨论使用 Pelican 初始化项目、创建文章、发布站点等基本操作。如果不熟悉这些基础知识,请查阅官方文档,或者搜索其他人写的教程。
总体目标¶
追求永恒,那永远也追求不到的永恒。
稍微具体一点,总体目标是:
- 长期写作
- 永久保存:永久地在互联网上留下一点痕迹
- 完全免费:不需要购买服务器、域名
- 免日常维护:一劳永逸,不需要操心服务器和域名续费、升级带宽、升级软件打补丁、部署 CDN、防 DDoS、防恶意消耗流量费用等工作
- 安全
- 安全的技术方案、网络协议,减少攻击面
- 掌握数据,数据可备份,保证数据的机密性、完整性、可用性

- 隐私保护
- 防止敏感信息意外泄露
- 被遗忘权:只公开最新版本,历史版本仅自己可见
- 自由:没有(此处删去 8 个字)
- 可定制
- 减少依赖,降低耦合度
- 使用相对 URL,不使用绝对 URL,可以通过任何协议、域名、端口、子路径正常访问
- 不使用第三方图床、CDN、web fonts 等,可以在离线场景下正常访问
- 使用 Markdown 等通用格式的纯文本源文件,不依赖某种特定软件和服务,可以版本控制,方便备份原稿,方便迁移
当然,没有完美的方案,我们只能尽可能实现这些目标。又想免费,又想要彻底的隐私,又想省事,又想要可控性,这往往是不可能的,往往需要做出一定的牺牲和妥协。
选择战略方案¶
“……于是他们告诉我,基于现代科学在各个学科最先进的理论和技术,根据大量的理论研究和实验的结果,通过对大量方案的综合分析和比较,他们已经得出了把信息保存一亿年左右的方法,他们强调,这是目前已知的唯一可行的方法,它就是——”罗辑把拐杖高举过头,白发长须舞动着,看上去像分开红海的摩西,庄严地喊道,“把字刻在石头上!”
——《三体 III:死神永生》,刘慈欣著
技术选型和服务器选择¶
洒家不推荐自己在服务器上搭建 WordPress 服务。因为对于一个长期运行的博客而言,维护自己的服务器需要很多精力。除非你搭好网站就撒手不管,信奉“能用就行”的信条,否则你需要定期备份,及时更新,遇到大版本升级可能会有数据库结构变化等麻烦问题,爆出安全漏洞需要及时打补丁升级,万一被攻击还要花时间解决(案例 1.1,案例 1.2,案例 2)。此外还需要操心域名和服务器费用、流量限额等问题,一旦停止续费,网站就没了。如果你是 feed 用户,看看你的阅读器的订阅列表吧,有多少订阅源已经报错无法访问了。正如关闭了我的 Wordpress 和 Linode 这篇文章所说,如果你喜欢 WordPress,使用商业版 WordPress.com 这种 WordPress 托管服务才是唯一正路。如果想省事,不如直接用 WordPress 托管服务、Blogger 等博客平台,把运维工作交给专业运维。这些就不在本文讨论的内容范围之内了。
洒家更不推荐使用自家的电力和网络折腾树莓派和内网穿透。家里的电力和网络的稳定性和可用性和数据中心没法比,树莓派的硬件稳定性也比不上专业的服务器。
洒家选择生成静态博客网站,这样一次生成就可以永久访问,不会像 WordPress 一样需要经常打补丁升级。洒家把文件储存到 GitHub Pages 上,并直接使用它提供的 <username>.github.io 域名,这样完全免费并且免运维。
除了 GitHub Pages 之外,还有其他的静态网站托管平台,例如 Netlify,以及 2020 年 12 月刚出的 Cloudflare Pages。洒家都没有用过,就不多介绍了。
GitHub Pages 的缺点¶
首先,我们无法直接拿到网站的访问日志,只能借助 Google Analytics 这些基于前端的工具查看访问情况。
另外,目前(2020 年 11 月)免费用户无法从私有 Git 仓库部署 GitHub Pages 站点。博客和开源代码略有不同,有时候我们只想公开最新的状态,而并不需要公开历史记录,因为我们有时可能会因为粗心大意而泄露隐私。举个例子,一个人可能使用了半透明的终端背景,想截个图贴到博客里,截图的时候窗口后面正好有一个密码管理器,把里面的手机号、身份证号、银行卡号和密码全截了下来,2 年后才发现。这时候直接删掉文件是不行的,谁都能看到 Git 的提交历史,恢复删掉的文件;想把仓库整个删掉,又发现很多人把 fork 当 star 用,这时已经有几十个 fork 了,删除别人的 fork 更是不可能。还有的人因为年少无知,Git 配置不当,commit 记录泄露了自己的真实邮箱。虽然 GitHub Pages 是公开的,信息一旦公开就不再可控,但是如果从一开始就使用私有仓库,就可以大大减少发现信息泄露时补救的难度。
因此,洒家使用教育邮箱申请了个免费的 GitHub Pro 教育优惠,可以从私有仓库部署 GitHub Pages 站点。
2022 年 11 月,洒家申请的这个教育优惠到期了。目前免费用户还是无法从私有仓库部署 GitHub Pages 站点。虽然之前的设置都没变,私有仓库没有自动变成公开仓库,GitHub Pages 站点也没有被撤销,但是洒家发现新的提交不会跟着发布到 GitHub Pages 站点上了。于是洒家又研究了一下,搞出了一套新方案。目前 GitHub 已经支持从 GitHub Actions 部署 GitHub Pages 站点了。而 GitHub Actions 又可以联网,我们可以先把静态网站打包、加密一下,存到自己的服务器,甚至 Litterbox 上,然后用 GitHub Actions 远程下载下来并直接发布到 GitHub Pages,不用在 Git 仓库中存储任何静态网站文件。大伙可以前往仓库 Phuker/phuker.github.io 查看这套方案,如果觉得不错也可以 fork 后使用。
另附一种以前想到的不完美的方案,仅供参考:同时使用 2 个 Git 仓库,分别设置不同的权限来缓解此问题。
- 博客源文件:设置为私有仓库,这个仓库的数据最重要,所有 commit 历史记录都要保留,从源文件生成的历史静态文件最好也保留下来,不要使用
.gitignore屏蔽。 - 生成的静态网站文件:设置为公开仓库,每次都 force push,抹掉历史,最大程度减少公开的信息量(类似这篇文章的做法:Host on Github Pages from a private repo: step-by-step guide)。
是否选择使用独立域名?¶
洒家的博客没有使用独立域名。域名具有独占性和稀缺性,它的收费方式实际上是订阅制而不是买断制的,我们无法永久购买域名,所谓的购买实际上是租赁。就算想长期续费,一般一次最多也只能续费 10 年。在可预见的未来,一旦停止续费,域名就会被释放,网站就消失了,这不符合上面提到的“永恒”的目标。而直接使用 GitHub 提供的 <username>.github.io 域名则在可预见的未来避免了这个问题。
但是直接使用 <username>.github.io 域名也有一些问题。首先,有些人(例 1,例 2)认为独立博客应该有个独立域名,没有独立域名的博客就不能叫独立博客。<username>.github.io 这种子域名则显得不那么独立。另外,域名是互联网的重要入口,掌握了域名就掌握了更多主动权和控制权。而 GitHub 也不是永恒的,它提供的 <username>.github.io 域名的寿命也只能达到 GitHub Pages 这款产品的寿命。万一微软大刀部把 GitHub Pages 产品一刀砍掉了,网站就会消失,指向它的所有链接都会失效。
所以,如果你有自己的域名,计划长期续费(起码一次性续满 10 年吧?),也可以给 GitHub Pages 设置一个自定义域名。使用独立域名,仍然可以同时使用别人的托管服务,自己只需要按时给域名续费,平均每年只需要投入百十块钱的金钱成本,不需要持续投入运维成本,这是最兼顾方便和可控的方案,值得推荐。如果以后 GitHub Pages 出现不测,或者不想用 GitHub Pages 了,可以随意迁移,域名不变 URL 就可以不变,不用担心读者流失、链接失效。如果除了域名之外你还有服务器,计划长期续费,持续付出运维成本,可以随时把静态文件迁移到自己的服务器上,可控性和自由度都很高。(使用自己的服务器时,建议从一开始就套上一层 Cloudflare CDN,节约服务器流量,隐藏源站,并防止 DDoS 等网络攻击。)
假设域名可以买断(即使是几十位的 hash 乱码),洒家倒是很乐意给博客搞一个独立域名。洒家设想,也许可以有一个顶级域名(此处设为 .foo),只允许将某种公钥的指纹注册为二级域名(以洒家的 GPG 公钥为例,可以注册为 7bc239159dd21bdc4909e08963b7492574828bad.foo,或者 Base32 编码一下变成 ppbdsfm52in5ysij4cewhn2jev2ifc5n.foo)。再设计一套开放的协议,通过简单的客户端程序即可实现自动鉴权,授权后可以操控 DNS 记录,之后 DNS 记录可以永久生效。价格策略可以是免费,一次性付费,修改时付费,或者一次付费后限时修改。实际上,在一些特殊的网络中已经有类似的域名了。例如,Tor 网络的 .onion 域名就是从公钥导出的乱码。然而,这类域名的缺点也显而易见,对于普通人来说,它们既难记又难输入,即使现在需要手动输入域名的场合已经变少了。
其他非常规方案¶
现在又出现了 IPFS 分布式网络这种新玩意,Cloudflare 也推出了自家的 IPFS Gateway,有的人已经把自己的博客部署到 IPFS 上了。这种方案确实很新鲜,但是也有很多问题。首先博客不一定适合去中心化的分布式网络。洒家也不确定 IPFS 的前景,不知道它能活多久。另外,节点和 Gateway 会定期进行垃圾收集,如果缓存被全部清除,冷启动访问就会很慢,可能还需要折腾 IPFS pinning service。使用 DNSLink 时,DNS 缓存过期时间又是个问题。因此,个人认为 IPFS 玩一玩,折腾折腾还行,但是不一定适合需要长期稳定运行的服务。
最后再介绍几种我见过的剑走偏锋的奇葩解决方案:
- 把生成文档用的 MkDocs 当博客生成器,示例:https://notes.ydlan.cn/
- 直接把 GitHub Issues 当博客,示例:https://github.com/rainzhaojy/blogs/issues
- 直接用
.txt纯文本文件当博客,例如著名的方舟子的新语丝,2021 年了博文还是GB系列编码,LF换行符,每行 35 个汉字硬换行的.txt纯文本文件
其实说到底,博客最重要的是内容,博客的本质就是一个能公开写字的地方,能公开写字的地方就是“博客”。虽然这些博客的形式很奇葩,但是只要坚持写博客,就应当鼓励。不过,洒家还是想提一个建议,其实一个“正常”的博客搭起来并不麻烦。
选择静态博客生成器¶
目前流行的静态博客生成器主要有:
- Jekyll:基于 Ruby,GitHub Pages 中已经集成了 Jekyll,
push源文件后 GitHub 就会自动帮你生成静态文件 - Hexo:基于 Node.js
- Hugo:基于 Go 语言,生成速度较快
- Pelican:基于 Python、Jinja 模板引擎和 Python-Markdown 转换器
不懂技术、不想折腾的用户一般可以先挑主题,然后再选择框架(所以生成器自带几套漂亮的主题很重要)。喜欢折腾的用户一般会选择自己最熟悉的语言写的生成器。洒家经常使用 Python 搞事,用 Flask 写过小网站,另外三天两头遇到内卷 SSTI CTF Web 题目,比较熟悉 Python、Jinja 和 Python-Markdown,有能力自己定制这套解决方案(例如修改模板、开发插件等),所以选择使用 Pelican 这款静态博客生成器。
Pelican 的配置文件就是一个 Python 代码文件,具有编程语言的严谨性,同时表现力强,比使用 YAML 格式配置文件的某些生成器不知道高到哪里去了。YAML 就是个坑爹货,过于复杂,而且不严格。此处不过多地对它进行批判,如果想深入研究,可以读一读 YAML: probably not so great after all 这篇文章。此文写得何等好啊!
洒家看到 Hugo 这款 Go 语言写的生成器首页宣称:
The world’s fastest framework for building websites
不用怀疑,编译型语言的速度肯定比 Python 不知道高到哪里去了。但是,个人认为生成速度并不是选择某一款框架的首要理由,因为静态网站只需要一次生成就可以任意次访问,相比于实时生成的动态网页,一定程度上可以接受较慢的速度,个人认为 10 秒钟之内都是可以接受的。洒家的博客目前一共有 32 个大小不一的 .md 文件,在当前配置下完整生成只需要大约 3 - 4 秒钟。写文章的时候也并不需要改一笔就运行一次完整生成命令,程序可以持续运行,监控文件变化并立即重新生成静态文件,花费的时间更短。
定制 Markdown 方言¶
如果你用 Markdown 写东西写多了就会发现,Markdown 原始的语法不太够用。Pelican 支持安装 Python-Markdown 扩展程序,洒家使用了一些内置官方扩展、自己写的扩展、自己魔改的扩展和第三方扩展,定制了一套 Markdown 方言。这套方言和 GitHub Flavored Markdown (GFM) 类似但是有不同之处。它支持目录、警告信息横幅、删除线、任务列表等语法。但是它不支持 URL 自动转换为链接,因为洒家认为语法应该保持明确,否则就会乱套。洒家以前启用了段落内换行时自动插入 <br> 的扩展,后来发现它容易和其他语法冲突,乱加 <br>。并且洒家写得很标准,也用不上这个功能,于是就把这个扩展关掉了。此处推荐一下洒家的 Markdown 转 HTML 工具 Phuker/md2html,它的扩展配置和此博客基本上一致。
洒家创建了一个测试页面,可以测试很多可能用到的标准的和非标准的 Markdown 语法的渲染和显示效果。
说起 Markdown,就不得不吐槽它的缺点。个人认为 Markdown 的语法里,最不方便的东西就是表格。手动编辑 Markdown 表格的时候,完全就是在用符号画表格,而且还不方便在格内换行(只能手动插入 <br />)。但是我也设计不出更好用的语法,毕竟这是用来手动输入的纯文本格式,不容易用简单的语法表示表格这种复杂的结构。所以洒家平时一般都会用无序列表来代替简单的表格。如果一定要用表格,洒家会临时切换到 Typora 编辑器,它可以自动把表格的 Markdown 源码排列整齐。
另外,Markdown 不支持不会被转换到 HTML 的注释。如果想加只有自己能看到的注释,只能用一些 hack 技巧,或者写扩展程序。洒家用的是第二种方法,可以在测试页面看到效果。
定制主题¶
此处假设读者对字体、审美、设计等知识已经有了基础的了解。如果不了解,建议去简单学一学。理科生不能光会自己那一套专业技术,这些东西以及文史政经哲也很重要。它们虽然不能直接帮你赚到钱,但是可以改变我们看世界的方式,多少应该了解一点。顺便推荐一下《写给大家看的设计书》,这是一本知名的入门级设计书,非专业设计师也可以看,洒家这个外行看了觉得很有收获。内容包括作者总结的 4 条设计的基本原则,以及一些关于色彩和字体的知识。我们也许可以凭直觉分辨出哪些设计更好,哪些设计不好,学习了有关理论之后,还可以说出好的为什么好,不好的为什么不好,怎么把不好的设计改得更好。
另外,洒家发现在定制主题的过程中,摘掉自己对作品的已知信息和已有习惯的“有色眼镜”确实很难,看习惯之后就会对作品的缺点视而不见,进行了客观上的优化之后,主观上甚至会觉得很不习惯,非常刺眼,想要改回来。个人认为,我们在做设计的时候,要有一种对自己内心深处的直觉的感知力,要尽量用对作品一无所知的人甚至婴儿的眼光去审视一切,听一听“他们”的感受。洒家在搞出新东西之后,经常会先晾在一边,过几天再看,往往就能重获新的眼光。
回到博客的主题。洒家的目标是做一个简约而不简单的技术性博客网站主题,大致目标如下:
- 简约:不要过于花里胡哨,要砍掉一切没用的元素,尤其是喧宾夺主的元素。例如:背景音乐、小挂件、阅读进度条、无意义的统计信息、容易和正文混淆的随机名人名言、和内容无关的题图、内容复杂别有洞天的侧边展开菜单、高概率触发的标签页标题变化彩蛋、默认弹出的遮挡视线的提示框。
- 直接:直接显示文章列表和文章内容,不要搞缓慢的过场动画和加载动画。正文页面不要再搞一个没意义的点击展开阅读全文按钮。首页直接显示文章列表,不要搞花里胡哨的个人介绍以及技能进度条。(技能进度条这种东西毫无意义,
PHP = 90%到底是个什么鬼意思?) - 逻辑清晰,结构合理:网站整体和具体页面结构清晰,页面元素位置合理,最常用的东西放在最容易找到的地方,按钮和链接的功能易于理解,交互逻辑符合直觉。例如,个人认为对于文章页面,应该在开头显示文章的发布时间等元信息,这样信息展示的顺序比较自然,也并不会占据太多空间;而不应该放在文章末尾,让想看发布时间的读者从开头翻到末尾再翻回来。
- 适当的交互反馈:当用户对可交互的元素(链接、导航栏、返回顶部按钮等)产生鼠标悬停、点击等操作时,用动画等形式进行适当的反馈。
- 兼容性强:响应式设计,以桌面端为主,兼容尺寸较小的移动端屏幕。以 Chrome 为主,同时尽量兼容各种主流平台的主流浏览器。同时,尽量适配打印机、无障碍、浏览器阅读器视图等比较少见的使用场景。
- 完全离线,加载速度快:无 CDN,无 web fonts。
- 不依赖 JavaScript:核心部分只使用 HTML 和 CSS,禁用 JavaScript 时依然能正常浏览,方便保存网页,对网页存档服务友好。
- 自主可控:可以随意定制修改,安全加固,且确保不含恶意代码。
动画¶
加载动画方面,洒家最讨厌的就是 Hexo 的 NexT 主题,每次打开页面就看见一片空白,然后是一个缓慢的动画效果,卡,卡,卡,三停顿才能看到正文,看见就觉得急。洒家对动画效果和心理的关系没啥研究,只想说加载动画可以用在内容加载完毕之前来缓解用户的焦虑感,而不应该在内容明明已经加载完的时候,硬加动画增加用户的焦虑感。如果一定要加上加载动画,把速度调快一些,效果可能会更好。人类的反应时间一般在 200ms 左右,洒家一般会把动画效果的速度设置为这个值附近。
洒家给页面各处添加了交互反馈动画效果,这样用户体验比较自然,不生硬。当鼠标指针经过或指向导航栏、返回顶部按钮、章节符号(¶)等元素时,会有淡入和淡出的效果。点击锚链接、返回顶部按钮时,页面会平滑滚动到目标位置。
背景¶
背景方面,洒家最讨厌的就是一些随机二次元图片背景主题,正文区域的透明度还调得很高,透过正文仍然能看到一大片花里胡哨的背景(这得是多爱二次元啊)。这里并不是说不应该加背景图片、背景动画,也不是说反对二次元,而是想说背景不是前景,不能喧宾夺主,过多地吸引读者的注意力,影响看文章。相反,只要读者在看正文,就不会注意到背景;但是当读者把注意力放在背景上,却又能发现一些意趣,这就达到了一种更好的境界。
浏览器兼容性¶
浏览器兼容性方面,洒家以 Chrome 为主要标准,尽可能兼容 Firefox 和 Safari,但是显示效果可能有一些小区别。至于 IE,洒家一开始都不敢用它打开这个网站,后来用 IE 11 试了一下(我可不想试 IE 6 和 IE 8),竟然可以基本上正常显示,只有一些小毛病。

(图片来源:I downloaded Chrome on my Samsung smart fridge so it became an oven.)
字体¶
这是一个以中文为主体的技术性博客,包含少量英文,因此洒家把所有的中文都设置成了无衬线字体,把所有的英文都设置成了等宽字体。相反,如果是一个英文博客,洒家会选择让普通正文使用无衬线字体,只在行内代码和代码块使用等宽字体,这样可能会更美观。
当然,人们的审美偏好不同,设计思路不同,可能会选择不同的字体类型。例如,很多人更喜欢有衬线字体,很多极客风格主题的网站可能会使用等宽字体和暗色背景突出风格。
洒家受到了谢益辉的楷体这篇文章的启发,修改了引用文字的外观。一般的主题往往会把引用文字设置为斜体。斜体比较适合西文,却不太适合中文,这时候正是运用楷体、宋体、仿宋等字体的好时候。洒家一开始试着用了楷体,后来发现楷体虽然在 Mac 的视网膜屏幕上显示效果很理想,在 Windows 机器的低像素密度的屏幕上却不太清晰。洒家又尝试增大字号,但是由于页面空间限制,字号只能稍微增大一点点,显示效果还是不清晰,字和字之间细微的字号区别也显得不太舒服。最后,洒家把字体换成了宋体。横平竖直的宋体在低像素密度的屏幕上的显示效果尚可,和正文的黑体恰好也可以形成对比。
引用文字的字体效果如下:
念奴娇·赤壁怀古
苏轼
大江东去,浪淘尽,千古风流人物。故垒西边,人道是,三国周郎赤壁。乱石崩云,惊涛裂岸,卷起千堆雪。江山如画,一时多少豪杰!
遥想公瑾当年,小乔初嫁了,雄姿英发。羽扇纶巾,谈笑间,强虏灰飞烟灭。故国神游,多情应笑我,早生华发。人生如梦,一尊还酹江月。
不过,目前多数移动设备只预装了黑体,并没有预装楷体和宋体,在这些设备上,引用文字的字体可能无法正确显示。
洒家没有使用 web fonts,只使用了系统自带字体。这样不会依赖外部资源,不用折腾 CDN,可以提高网站加载速度,比较简单,显示效果也不差。当然,这样会缺少独特字体的设计感,无法做到字体在各种操作系统上的完全一致性,只能保持字体种类的一致性。对于楷体这些使用较少的字体,连字体种类的一致性都无法保持,在一些设备上会显示为默认的黑体。但是对一个博客而言,这些都是次要问题。
下面是一些关于系统预装字体的好康的东西:
- CSS Font Stack:查询各种西文字体在 Windows 和 macOS 上的预装情况
- Fonts.css:一套跨平台中文字体 CSS 解决方案,只需指定中文字体类型即可
- Fonts.css Demo:Fonts.css 的预览和测试页面
页面对少数场景的适应性¶
这个小节不谈响应式设计和浏览器兼容性这些显学,而是要聊一些更不显眼的使用场景的处理方法。洒家不是专业前端,前端代码都是乱写的。以我有限的一点点经验也能感受到前端工作的坑很多,不仅需要处理不同大小的屏幕、不同的浏览器等常见问题,还需要处理各种例外情况,处理各种比较少见的使用场景。对于主题作者来说,多考虑到一点细节就能实实在在地帮到一小部分人。
网页不仅可以显示到屏幕上,还可以通过打印机打印到纸上。纸张和屏幕有很大不同,纸张的“可视区域”是离散的,需要分页;纸张是“死”的,不可交互;我们需要用碳粉或者墨水来打印,为了节约耗材并提高打印速度,应该避免打印大面积的色块。为了处理这些问题,我们可以在 CSS 中使用 @media print 媒体查询,在打印网页时,对页面稍加处理。我们可以适当设置页边距,删除背景图片和背景动画,重置背景色,重新设置文字的字体、字号和颜色,删除广告、导航栏、评论输入框等不必要、可交互的元素。具体操作可以参考:
目前浏览器已经支持在 CSS 中使用 @media 媒体查询检测 prefers-color-scheme 媒体特性,当操作系统的全局主题颜色设置为暗色时,自动应用暗色配色方案。(洒家暂时没打算搞,同时再设计一套配色方案有点麻烦。)具体操作可以参考:
- CSS-Tricks, Robin Rendle: Dark Mode in CSS,2018-11-14
我定制的主题¶
如果想要自己定制主题,可以从选择一套简洁的基础主题开始,而不必一切都从零开始。过于花哨的主题修改起来更麻烦,基础的代码越简单,对于精力有限的个人来说就越容易处理。洒家当时选择的是 blueidea 主题,后来不知怎么着,手一痒就走上了定制主题的不归路。
经过我这几年断断续续的魔改,这套主题和原主题相比变化显著。洒家增加了 QQ 登录界面三角形动画效果背景,为了防止喧宾夺主,洒家把动画速度和 FPS 调得非常低(这样顺便还降低了功耗,防止风扇狂转),正文区域的透明度也设置得较低。另外删除了影响加载速度的在线字体,调整了很多结构和样式。
洒家不是专业前端和设计师,前端代码都是乱写的。前端的坑太多了,CSS、浏览器兼容性全是坑。CSS 属性之间不正交,洒家也没系统学过,就会用试错法“面向巧合编程”,按下葫芦浮起瓢。

(图片来源:When you decide to rewrite the CSS)
洒家目前不准备开源这套主题。上文提到,本人前端水平有限,很多地方还有一些细节问题。此外,这套主题已经针对我自己的需求高度定制化,和我的配置文件耦合太深(例如使用了自定义的 Jinja filter),删掉了很多对其他人可能有用的功能(例如分页功能),不一定符合 Pelican 的标准主题约定,在别人的配置下不一定能正常工作,因此不太适合作为独立的主题开源。如果要开源,可能需要以开箱即用的形式,把只针对我自己的特有内容(文章源文件,部分配置)和针对所有人的可复用内容(主题,另一部分配置,插件)切分成 2 个仓库,这还需要花费很多额外的精力。
折腾主题耗时巨大,完美的极限存在1却永无止境。如果你也想折腾出一套漂亮的主题,洒家建议适可而止,不要本末倒置,在主题上花费过多时间,而是把更多时间花在写博客上。
第三方服务¶
下面是洒家在这个博客上试玩的一些好玩的第三方服务。
Disqus 评论系统¶
静态网站没有后台,没有数据库,只能嵌入第三方评论系统。洒家使用的是 Disqus 评论系统。Disqus 什么都好,唯一的问题就是被墙了。不过洒家认为,这个博客的读者应该都能解决这个问题。
市面上还有很多其他的评论系统方案。以前国内有过一个类似的评论系统,叫做“多说”,可惜在 2017 年 6 月倒闭了(相关讨论)。
以上这些都是正规的评论系统。市面上还有一些走野路子的评论系统,例如基于 GitHub Issues 的评论系统 Gitment 和 Gitalk,基于 LeanCloud 的评论系统 Valine,还有 Valine 的衍生品 Waline。这些方案虽然很有新意,但是有些存在安全隐患,有的明显存在无法解决的安全问题。洒家除了 Disqus,其他评论系统没用过,也没仔细研究过。只是建议博主和读者使用前仔细研究其原理,是否存在安全隐患和问题。
Google Analytics 统计¶
上文提到,我们无法从 GitHub Pages 拿到网站的访问日志,只能借助 Google Analytics 这些基于前端的工具查看和统计访问情况。和后端的日志相比,通过前端统计也有它的优势,不仅可以看到用户是什么时候来的,还可以看到用户是什么时候走的,可以分析用户的行为。此外它还可以用来统计访客数量、访客所在的地区、获取流量的渠道等。
Google Analytics 的功能看起来很全,但是洒家找了好多天也没找到类似网站日志的东西。洒家只想拿到一张表,上面记录最近几天的几点几分,从哪个地理位置,有一个什么类型的设备,访问了什么页面。搜了一波好像无法在网页直接看,还要调用 API,挺麻烦。
Google Search Console 统计搜索引擎情况¶
洒家顺便又玩了一下 Google Search Console,用来简单搞点 SEO。它有一个请求编入索引功能(request indexing tool),可以随时给 Google 爬虫手动提交 URL,网页当场就能被抓取并显示在 Google 搜索结果中。它还可以用来查看 Google 搜索关键词,点击率等统计情况。
Google AdSense 广告¶
天下熙熙,皆为利来;天下壤壤,皆为利往。——《史记·货殖列传》
洒家以前和大多数人一样,看见广告就烦。但是当我这些年写过博客,当过 Bilibili 的小 Up 主之后,我的想法发生了一些改变。这个世界不是乌托邦,不是天堂,人如果想活着,就要“恰饭”。如果人不“恰饭”,就会死。人们创作内容往往开始于兴趣爱好,如果想要创作更高质量的内容,往往需要投入越来越多的时间,甚至全职工作。一个全职内容创作者,除非家里有矿,用爱发电,否则一定是要恰饭的嘛。
那么无论是做影视还是音乐,软件还是游戏,当一个内容创作者创作出好的作品,有了流量,怎么维持生存,怎么可持续发展,怎么实现“流量变现”?无非是通过广告,“带货”(电商变现),用户捐款打赏,增值服务,收费制等方式。其中,广告是一条最简单、最常见的道路。
简单地调查一下 YouTube 和 Bilibili 就可以知道,二者目前的商业模式和盈利结构有很大不同。YouTube 主要靠广告盈利,视频页面有较多广告,视频片头有几秒钟后可跳过的广告,视频中间也会插播广告。Bilibili 目前主要靠游戏盈利,广告收入比例很少,并且 B 站从一开始的特色就是无片头广告。
洒家并不想在这深入扒一扒它们的招股书和财报,对着它们的商业模式一顿分析,只是想从内容创作者的角度,讨论一下内容创作者的生存问题。根据一些 Up 主的统计,在相同播放量的情况下,Bilibili 的流量分成要比 YouTube 少接近十倍甚至几十倍。在 Bilibili,一个几十万粉丝的 Up 主,一年流量分成就几万块钱,说难听点,够干啥的?更不用说只有几万粉丝的 Up 主了。
因此,就算 Bilibili 没有片头广告和插播广告,我们还是要看广告,只是广告的形式变成了“恰饭”,变成了“猝不及防”。Up 主练就了一身花式恰饭的本事,观众长出了能感觉到广告“要来了”的灵敏嗅觉,“恰饭”成了 Bilibili 的特色之一。能恰到饭的还算好的,在成长为流量金字塔顶端的少数人之前,小 Up 主连饭都没得恰,只能用爱发电。考虑一下,业余小 Up 主怎么生存?如何收回时间成本?连合作推广都接不来怎么办?做的鬼畜、哲♂学不适合植入广告,小众内容甲方看不上怎么办?要不要恰烂钱?
个人认为,大 Up 主都是从小 Up 主一步一步走过来的,流量分成是小 Up 主成长过程中唯一能依靠的东西。增加流量分成,更能保护一些小众 Up 主,促进小 Up 主自己和整个平台的发展。而增加流量分成,让整个平台转亏为盈,可能还是要靠广告。在理想的情况下,专业的事交给专业的人,接广告投放广告交给平台,Up 主只需要专心做视频就能得到可观的收入。
然而广告和用户体验是矛盾的,加广告很难不影响用户体验。一个好的商业模式一定会在盈利和用户体验之间找到一个平衡点。个人认为对于视频网站而言,如果要加视频片头广告,3 - 5 秒后可跳过的形式相对可以接受,几秒钟后可跳过的广告对广告主和用户都有好处。视频画面区域旁边的广告可以接受,而中间突然插播的广告相对不可接受。同时,内容创作者可以自由选择是否不在自己的内容上加广告,自愿用爱发电。对广告敏感的用户,嫌广告浪费时间,一点都不想看到广告,可以用去广告插件完全去除广告,而不是只能去掉广告,去不掉黑屏和 120 秒倒计时。洒家自己也给所有浏览器都安装了 Adblock Plus 去广告插件,平常根本看不到 YouTube 的片头广告。
Adblock Plus 方面也意识到了这个问题,提出了可接受广告(acceptable ads)概念。默认情况下,Adblock Plus 允许显示不影响正常浏览体验的非侵入式广告。广告发布商可以对符合条件的广告位提交申请,添加到白名单中。由于审核和管理需要人力成本,Adblock Plus 会对大型广告发布商收费,但是对小网站免费。
当然,上面提到的问题都是没有最终答案的。并不是说哪一个平台是完美的,哪一种商业模式是完全合理的,能让平台、创作者和用户都舒服;也不是说有了足够的流量分成就不用“恰饭”了。每个平台都有自己的特色,平台和平台之间不能一概而论。还要应该让不同的平台保持多样化,探索出不同的道路。与其追求唯一正确的终极答案,内容创作者和用户的选择的权利才是更重要的。
关于广告、商业化、内容创作、流量变现这些大话题,最后再放几个视频:
- KatAndSid:做 3 年视频一共能赚多少钱?,2019-05-13
- 机智的党妹:【党妹】300 万粉全职 up 主到底有多赚钱?,2019-08-14(注:这是原视频的备份,2021 年 8 月原作者机智的党妹宣布退网并下架所有视频,原视频地址已无法观看)
- 街森:央视记者提问 B 站董事长:听说当全职 UP 主能赚大钱?,2019-10-25
- 柴知道:【柴知道】B 站和微博的财报里藏着哪些门道?看财报到底能看出哪些信息?,2020-11-13
- NiceChord(好和弦):我要“慢慢”离开 YouTube 了,你也应该跟我一起走~,2020-12-12,作者是官大为。视频介绍了 YouTube 广告策略、推荐系统、版权审查等方面的弊端,并介绍了 LBRY 这个去中心化的内容发布平台。作者自己的频道是无广告的,并且倾向于使用厂商商务合作、推出自己的商品、会员订阅制等更有主动权的方式盈利。
下面回到搭建博客的话题。洒家在博客里加广告,并不是想靠这几篇水文年入百万,只是想体验一下通过 Google AdSense 实现流量变现的过程。毕竟咱又不是知名博主,不是阮一峰,恰不了这碗饭。更何况 Google AdSense 需要攒 100 美元才能提现,目前这点访问量到猴年马月才能拿到钱,因此加广告纯属娱乐。另外,“己所不欲,勿施于人”,洒家也不想在自己的博客里加烦人的侵入式广告。目前洒家只在文章底部加了一个简单的横幅广告,只有看完文章的读者才会看到广告,应该说用户的体验和没加广告没啥区别了。
下面再来详细介绍一下 Google AdSense。
Google AdSense 的广告分为自动广告和广告单元。有了自动广告就什么都不用干,只需要把代码加到网页里,程序就会自己找地方展示广告。而广告单元则有更多可定制性,广告发布商可以控制广告的位置、形状、大小。
Google AdSense 每 1 个月会付款 1 次。余额设定了一些阈值,一旦余额达到了 10 美元,Google 就会给自己填的地址寄一封包含 PIN 码的信件(中国邮政,平邮)来验证地址是否正确。只有余额达到 100 美元才可以提现。广告的收入水平是动态的,展示和点击得到的收入并不固定。
页面中可能会出现各种各样的广告,可以使用“屏蔽控制功能”控制网站上展示的广告,例如可以屏蔽某些敏感类别的广告、基于用户的广告、含有动画的广告等。
值得注意的是,广告发布商在任何情况下尽量不要点击自己的广告。偶尔误点没有关系,Google 会自动判断并消掉无效的点击,但是如果频繁大量点击,可能号就没了,一分钱都别想取出来。
另外,去广告插件会影响 Google AdSense 页面中的部分功能。例如点击“屏蔽控制功能”按钮时,会报下面的错误:
我们此时无法处理您的请求,对于给您带来的不便之处,我们深表歉意。我们已向工程师通报了该问题,工程师将尽力为您解决。
如果遇到了这个问题,可以设置去广告插件的白名单。我们不必把整个 google.com 加入白名单,只需要编写过滤规则,把 google.com 的 /adsense/ 路径及其子路径添加到白名单。以 AdBlock Plus 为例,在 设置 - 高级 - 您的自定义过滤 中添加下面的规则即可。
@@||google.com/adsense/$document
Markdown 编辑器¶
个人认为,Markdown 编辑器是个伪需求。
洒家曾经用过 MarkdownPad、MacDown 这些两栏式 Markdown 编辑器。后来听说了 Typora,下载试用了一下,感到十分惊艳,于是当场把它设置成了 .md 文件的默认打开程序。用了一段时间,感觉有时候它总是读不懂我的心思,这时候就需要按 Ctrl + / 或 Command + / 快捷键切换到源代码编辑模式继续编辑。然而我经常切换过去,写着写着,却忘了切换回去了。我琢磨了一下,以后还是直接用写代码的 Visual Studio Code 写 Markdown 吧。
Markdown 是一门十分简单易学的语言。如果连这点语法都学不会,基本也就告别自行车了。当熟练了之后,通过所见即所得的方式间接地操作 Markdown 源代码,反而会感到隔靴搔痒,碍手碍脚。即使是两栏式编辑器,没输入几个字就预览一下,也是既没有必要又扰乱思路。洒家和谈谈 Markdown 编辑器这篇文章的观点一致,写 Markdown 只需要在一个带语法高亮的文本输入框里直接输入就可以了,这样可以保持最大的可控性,况且也并不麻烦。
操作流程¶
个人比较喜欢在本地生成静态文件,先预览静态文件的生成结果的变化,然后再手动提交,而不是稀里糊涂地先提交再看效果。这样可以加强对网站的控制程度,减少错误提交。更新设置、使用扩展程序、修改主题、升级程序版本、使用一些特殊的 Markdown 语法等情况下,这种操作很有用。因此,洒家没有使用 CI/CD 自动生成静态文件。不过 CI/CD 对于不喜欢折腾的普通用户确实很方便,甚至可以直接用手机在 GitHub 网页界面上修改 .md 文件,然后网站就自动更新了。
配好环境之后,日常的操作并不麻烦。写博客时,只需要运行一条命令,就可以在终端里启动本地 HTTP 服务 和 Pelican,然后启动浏览器和代码编辑器。本地 HTTP 服务用于实时预览页面效果,Pelican 则可以持续生成静态文件。运行 Pelican 时加上 --autoreload 参数,Pelican 会先重新生成所有静态文件,然后不退出,持续监控文件变化。修改文件后,Pelican 会立即重新生成静态文件,此时刷新浏览器即可预览。相比每次改完源文件都手动重新生成所有静态文件,这样方便操作,而且生成速度较快。
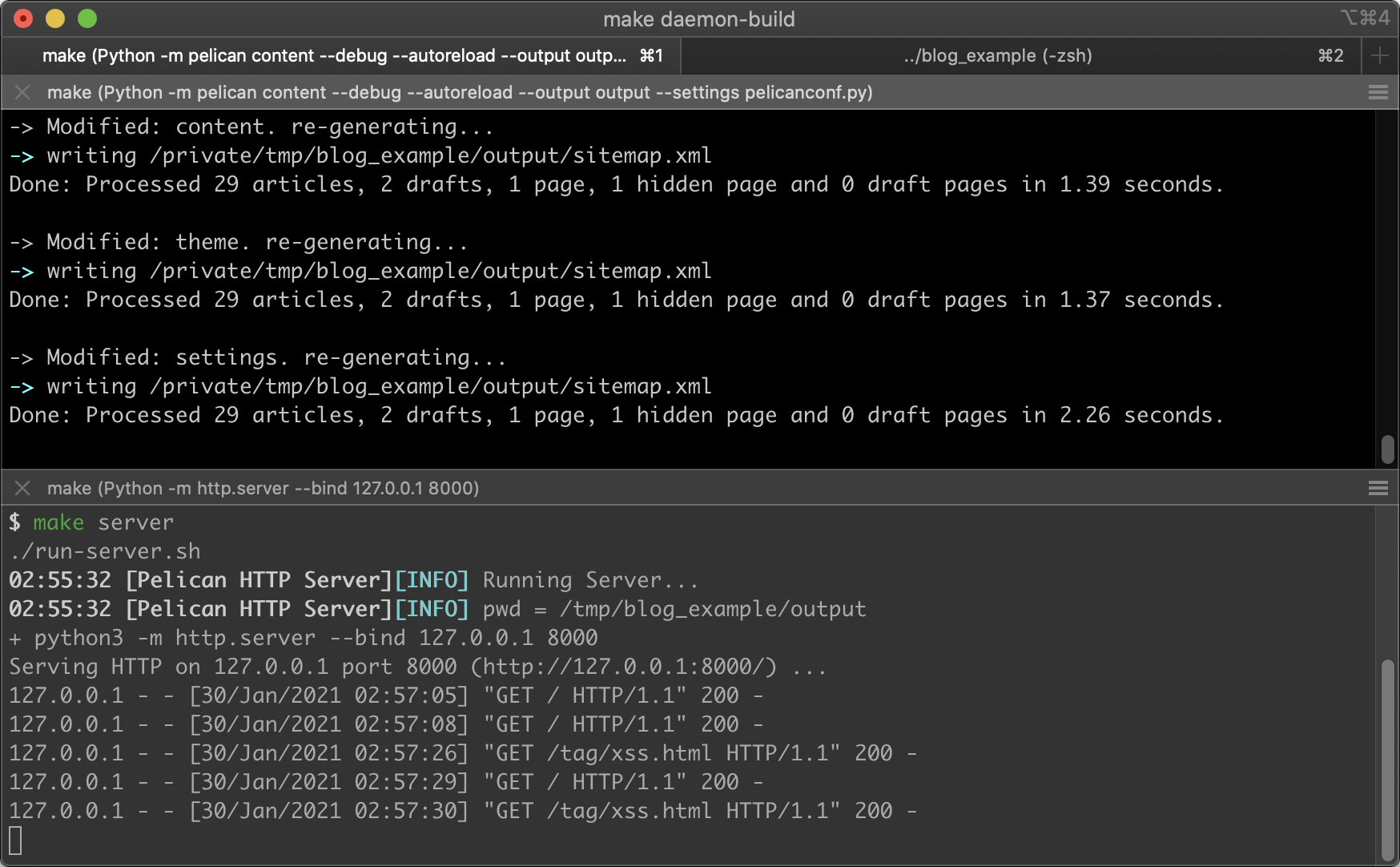
修改文章时,编辑 Markdown 源文件头部的 Modified 元信息,添加或更新修改时间。如果修改比较小,则不用更新。
写完博客后,先使用 Git 查看生成的静态文件发生了什么变化,然后运行脚本检查中西文混排等排版问题(见下文),最后再手动 commit 和 push。修改配置文件、主题文件后,更要仔细检查生成的静态文件的变化,查看哪些部分受到了修改的影响。
如果你不想在本地搭环境,可以使用 Forestry 这类服务。它相当于一个第三方的博客后台,可以替你操作仓库里静态博客的文件。授权访问 GitHub 之后,就可以像使用传统博客一样在网页上写文章了。当然,以洒家的性格,肯定是不会用的。
博客写什么?¶
个人认为,公开的博客不是私人笔记,博客里应该写一些有原创性、别人能看得懂、对他人有用的东西,而不应该 100% 复制粘贴,或者写一些只有自己能看得懂的笔记和流水账。只要能帮到他人,1 句话的博客也有价值,否则,粘贴再多也只是污染互联网环境罢了。
从利己的角度来说,写给别人看,其实也是写给自己看。对他人有用,也是对自己有用。那些只有自己看得懂的流水账就算不公开发布,作为私人笔记也是不合格的,只是“看起来很努力”而已。因为随着时间的流逝,知识会逐渐遗忘。作为作者,一年之后再打开,看到自己写的流水账,感觉说不定和其他人没有太大区别,连自己都看不懂了。
所以,无论是记笔记还是写博客,都要把前因后果、来龙去脉写明白。记笔记是个好习惯,但是个人建议先把笔记记在 OneNote、印象笔记这些软件里。记笔记可以比写博客适当简略一点,在能看得懂的情况下只记下要点。当笔记越记越多,挑出有用的内容整理一下,总结出来,就可以当成博客发出来了。
在 CSDN 平台里,有很大比例的博客可以作为典型的反例。那里充斥着互相抄袭了 114514 遍的垃圾“原创”博客,而且复制粘贴的时候连排版都没有做好,内容还有可能是错误、片面、过时的。有的人可能会说“我的博客只有我自己看”,但是他们也许没有想过,垃圾博客会污染别人的搜索引擎,不想看都不行。也许在垃圾堆里偶尔可以淘到珍宝,但是“可以”并不意味着“值得”。与其在垃圾堆里找宝贝,不如屏蔽 CSDN,用英文搜索问题。
也许 CSDN 曾经有过辉煌,但是那辉煌已经成为历史了。没有把大环境搞好,一手好牌打得稀烂,这是平台的责任,也是所有用户的损失。好的环境是什么样的?可以看一看 StackExchange。StackExchange 有一套声望值机制,低质量的问题和回答很快会被清理,是一个自我管理的良性社区。用户乐于分享,共同建设和维护社区,这个氛围是需要培养的。CSDN 也有问答平台和论坛,能望其项背吗?
如果你一定要公开地写一些只给自己看的东西,同时又不想污染搜索引擎,可以给 robots.txt 文件设置如下内容,避世绝俗,天下太平,岂不美哉?
User-agent: *
Disallow: /
一些细节¶
魔鬼藏在细节中。
下面是一些简单的细节和小技巧。这些并不是什么高深的东西,但是很容易被忽略。学会之后可能就会感觉显而易见,但是不知道的就是不知道。
正确使用 HTML Entity 编码¶
目前 Pelican 的最新版本为 4.5.1。根据 Pelican 的源码 pelican/settings.py,它默认没有使用 Jinja 的 autoescaping 功能。
分析 Pelican 自带的主题 notmyidea 的 templates/article.html 模板文件,文章页面输出标题 <title> 标签的部分代码为:
{% block title %}{{ article.title|striptags }}{% endblock %}
文章页面输出正文 HTML 的部分代码为:
<div class="entry-content">
{% include 'article_infos.html' %}
{{ article.content }}
</div><!-- /.entry-content -->
可以看出,需要 HTML Entity 编码的输出点全靠 striptags、escape 等 filter,有些输出点还有遗漏。
洒家认为 Pelican 这个设计是有问题的,但是这次主要问题并不是安全性(假设只有自己能控制源文件,没有任意输入点,不会有人注入 <script> 标签进行 XSS 攻击)。首先,在一些情况下,正常功能无法正常使用,例如如果文章标题和 article.summary 包含特殊字符,显示就会出问题。另外一个问题是不方便编写模板代码。实际上,只有少数变量输出时需要把 HTML 保持原样输出。例如 article.content、page.content 这些从 Markdown 转换而来的字符串变量,以及 LICENSE 等自定义变量。而其他大多数变量在输出时,都应该默认进行编码。因此,应该好好利用 Jinja 提供的功能,设置 autoescape Environment。
首先编辑配置文件 pelicanconf.py,设置 Jinja Environment:
JINJA_ENVIRONMENT = {
'autoescape': True,
}
然后修改模板,把 striptags、escape 这些 filter 该删的都删了,需要保留原始 HTML 的输出点加上 safe filter:
{{ article.content | safe }}
自动生成纯文本摘要¶
目前 Pelican 的最新版本为 4.5.1。根据 Pelican 自带的主题 notmyidea 的 templates/index.html 文件,这套主题的索引页面使用 article.summary 作为摘要:
{{ article.summary }}
洒家有时候不想写 summary,希望可以完善一下自动生成摘要的功能。如果文章带有 summary 属性,Pelican 会把它当作一串行内 Markdown 代码渲染,渲染结果储存在 article.summary 中。如果文章没有 summary 属性,Pelican 会自动把正文生成的 HTML 通过某种方法截断,然后储存在 article.summary 中。洒家曾经也试过手动截断 HTML,但是无论怎么截,HTML 格式的 summary 效果都不太好,都会遇到很多麻烦的问题。例如,正确判断截取的位置做起来很麻烦,相对路径的图片有时候无法加载,CSS 写起来也比较麻烦。
相比之下,从正文自动生成一段纯文本格式的摘要在技术上比较简单,可以使用 striptags filter,把上面的模板改为:
{{ article.content | striptags | truncate(275) }}
但是洒家还想在生成摘要的时候对 HTML 做一些处理。例如,我使用了 Python-Markdown 扩展 toc,想要把生成的 HTML 中的 div.toc 目录和 a.headerlink 链接(¶ 链接)等元素先去掉。然后再把 <img> 标签替换为 [图片] 字符串。这时候,Jinja 自带的 filter 就无法达到目的了。于是洒家编辑配置文件,用 BeautifulSoup 库写了一些自定义的 filter 函数 添加进去:
JINJA_FILTERS = {
'my_article_obj_to_text': my_article_obj_to_text,
'my_strip_rendered_summary': my_strip_rendered_summary,
}
修改配置项目,当没有写 summary 时,article.summary 为空字符串:
SUMMARY_MAX_LENGTH = 0
然后把模板改为:
{%- if article.summary -%}
{{ article.summary | my_strip_rendered_summary | safe }}
{%- else -%}
{{ article | my_article_obj_to_text | truncate(225) }}
{%- endif -%}
当手动写了 summary 时,my_strip_rendered_summary filter 会去掉开头的 <p> 和结尾的 </p>,然后直接输出。如果没有写 summary,my_article_obj_to_text filter 会从正文自动生成一定字数的纯文本。为了提高速度,洒家给后者这个 filter 函数加上了基于 hash(article.content) 的缓存。
这套代码还有一定的优化空间,Markdown 变成的 element tree 变成了 HTML 字符串,现在又把它 parse 回 element tree 了。如果想减少 parse 这一步骤,又需要想其他思路,然后折腾 Python-Markdown 和 Pelican 的扩展来实现。目测可以搞一个 Python-Markdown 的扩展,从 element tree 或者直接从 Markdown 提取文本字符串,然后把字符串写到 Meta Data 里面。(可以,但没必要。)
文章列表是否应该分页?¶
个人认为,个人博客的文章列表没必要分页。个人博客不是微博,也不是公共写作社区,一般来说,一个人写的文章再多也不过几百几千篇。把它们一次性全部显示出来其实并不会消耗太多浏览器资源,却可以让读者一目了然,还可以直接使用 Ctrl + F 快捷键搜索文章,搜索功能也就没必要做了。如果文章太多,可以不显示摘要,只显示标题。如果一定要坚持分页的做法,每页至少应该放 100 篇。
相反,如果别人来你的网站,想看看你都写了什么玩意,结果一打开每页只有 10 篇,点下一页又得卡好几秒,这就是在严重破坏浏览的连贯性,打击读者的积极性,到手的访客在一次一次的翻页中都损失了。即使主题做得再好看,其连贯性和实用性甚至还不如在设计界闻名的宏晶科技官网(笑)。
另外,洒家认为在首页放每一篇文章的全文,然后另做一个只有标题的目录页面也很不合适。首页是网站的入口,一点进去,一整篇好几页的文章糊到脸上,怎么翻都翻不到下一篇,让人感到窒息,感到一叶障目,不见泰山。个人认为目录就是目录,读者点开首页需要看到一个一目了然的目录,而不是一本只能从第一页开始读的没有目录的书。个人认为首页目录里面只放标题,或者只放标题和简短的摘要比较合适。
也有人在首页目录里面加载全文,但是默认只显示固定高度,同时搞一个点击展开阅读全文按钮。这种做法也可以接受,但是如果文章多了数据量大了,恐怕就又要翻页,动态加载全文,或者搞个自动加载的信息流了。
推荐谢益辉写的日志列表分页一文,洒家想说的都在里面了,可谓“眼前有景道不得,崔颢题诗在上头”。另外此人的其他文章写得也相当好,甚得我心,值得推荐。
是否应该使用图床?¶
图床并不适合所有人。个人认为对于大多数计算机类技术性个人博客来说,把图片和 HTML 放到一起即可,没有必要使用图床。
很多搭建博客的教程,动不动上来就开始折腾图床。使用图床有一些常见的理由:
- 为了减轻服务器的带宽、流量、并发和存储空间压力,减少成本,让各个地理位置和 ISP 的用户都能快速低延迟加载,“动静分离”,对图片资源做针对性优化。
- 需要全平台发表,一个 Markdown 文件可以在各大平台直接粘贴。
- 享受图床顺带的功能:自动处理图片,生成不同分辨率的图片,并自动添加水印。
- 有时候只能分享单个
.md文件,无法附加图片文件。
但是使用图床可能又会带来一些问题:
- 无法保证可用性:第三方图床随时都有倒闭的风险,在微博等平台上传图片并盗链作为图床也随时可能遭到反盗链措施。如果图床挂了,图片就会突然无法加载,甚至彻底丢失。很多老博客使用的第三方图床比博客活的时间都短,图片都已经加载不出来了,运气好的话还能在网页存档服务里找到它曾经的样子。
- 运维和迁移成本高:HTML 和图片是一个整体,把它们分开需要付出额外的成本。挂了一个免费图床,又费功夫换另一个,折腾得多了搞不好还要研究自动化图床搬家工具。
- 数据丢失:如果图床倒闭,同时你手里没有原图,那洒家就只能对你说一句节哀顺变了。
- 使用限制:上传图片文件时限制文件大小,上传图片后强制有损压缩图片,图像分辨率和质量不受控制地下降。
- 网络攻击:黑客恶意消耗收费图床的流量。
- 增加依赖:增加复杂性,无法在离线环境浏览。
图床也许是为了解决错误的问题的一块补丁。你真的遇到了需要用图床才能解决的问题了吗?你真的需要全平台发表文章,在互联网上制造重复内容吗?你的网站有起码几百张的大量图片吗?你真的需要放那么多和内容无关的花里胡哨的图片吗?图片是网站的主要内容,需要优先保证加载速度吗?文章写几篇了,真的有人看吗?你真的需要从一开始就自己搭建服务器,并且花费时间和精力运维吗?
所以,个人认为在图床上瞎折腾,是一种盲目的过早优化,会增加很多使用和维护成本,却得不到太多好处。除非你的博客里有成百上千张图片,你是摄影博主,同时你有众多的读者,否则不推荐使用图床,把图片和博客放到一起就可以了。HTML 和图片是一个整体,如果图片加载速度慢,那文字加载肯定也慢。如果以后确实需要优化,无论迁移还是套 CDN,作为一个整体处理更方便。
如果网站流量小,加载速度慢,个人建议整站直接套一层 CDN,然后配置一下缓存规则。例如 Cloudflare 用户可以使用页面规则功能,设置图片目录的边缘缓存 TTL(Edge Cache TTL),最长可以缓存 1 个月的时间。
如果还是想用图床,可以自建图床服务,把数据掌握在自己手中。可以自己在服务器上搭建图床服务,也可以使用一些云计算平台提供的对象存储服务。用于图床的服务器不仅需要速度快,还要离用户近,因此自建图床还是需要和 CDN 配合。
如果不想/不会自建图床,或者自建图床仍然满足不了要求,可以使用服务稳定,预计短期内不会倒闭的收费图床。如果你没钱但是有大把时间,可以尝试第三方免费图床,或者盗链。选择免费图床时要搞明白它怎么盈利的问题,不赚钱的免费服务终究还是要倒闭的。另外要清楚,在新浪微博、简书、某些云笔记当成图床,利用他们的服务器资源在自己的网站上显示自己的内容,属于盗链行为。商业公司不是慈善组织,如果他们不想被薅羊毛,分分钟让你的盗链图片失效。
最后,无论用哪个第三方图床,最重要的还是备份原图。
对于图片本身,还可以做一些其他工作。一般情况下,技术性博客里也不会有大量的图片。必要的图片可以使用 TinyPNG、ImageOptim 等工具,有损或者无损压缩到合适的分辨率和体积。而终端截图、代码截图一般都可以使用语法高亮的代码块代替,以终端截图为例,Markdown 代码
```console
root@ubuntu:~# id
uid=0(root) gid=0(root) groups=0(root)
root@ubuntu:~#
```
渲染的效果是
root@ubuntu:~# id
uid=0(root) gid=0(root) groups=0(root)
root@ubuntu:~#
这样不用额外插入图片,而且方便复制代码,也方便隐去一些敏感信息。
LaTeX 数学公式¶
这个功能目前对洒家似乎没有什么用,洒家翻遍所有博文也没找到使用的地方,但是还是把它实现出来了。目前也就只能在提到 LaTeX 时,把 LaTeX 变成  装个 X。
装个 X。
一般用户可以直接使用 MathJax、KaTeX 等浏览器端渲染方案,安装 Pelican 扩展 render-math 即可。也可以在浏览器端调用公式转图片 API,把公式变成 <img> 标签,src 属性指向 API 的 URL,这样更轻量,代码也很容易实现。
但是由于本文开头提到的理念,洒家想要一种简单,轻量,并且可以离线使用的解决方案。MathJax 等浏览器端渲染方案太重了,需要加载一堆 CSS 和 web fonts,影响加载速度,不方便做到离线。在浏览器端调用公式转图片 API 更是无法做到离线访问。洒家选择在生成网站静态文件阶段,把公式转换为 SVG 矢量图,编码成 Data URLs 放到 <img> 标签的 src 属性里,嵌入网页就可以了。洒家也不想本地搭环境,而是选择调用 math.now.sh API(还是基于 MathJax)。然后在硬盘里缓存请求结果,同一个公式只会请求一次。
对于 Markdown 的公式语法问题,个人认为不能照搬 的语法,否则 PHP 等 $ 符号很多的语言很容易出问题。个人认为 GitLab Flavored Markdown(也简称为 GFM)的语法比较科学,借用了 Markdown 原有的语法,行内公式使用 $` 和 `$ 包裹公式,例如 $`\lim_{x\rightarrow0} \frac{\sin(x)}{x} = 1`$,其渲染效果为 }{x} = 1") 。行间块级公式使用代码块语法
。行间块级公式使用代码块语法 ```math,同样的公式,渲染效果如下:
}{x} = 1")
洒家给 <img> 标签加上了 title 属性和 ondblclick 事件属性,鼠标放到上面可以看到它的 代码,双击时可以复制代码。
关于 Markdown 方言和数学公式语法的扩展阅读:
- MathJax 与 Markdown 的究极融合,谢益辉,2017-04-07
- 混乱的 Markdown 世界,谢益辉,2017-08-24
相对 URL vs. 绝对 URL¶
洒家搭网站喜欢用相对 URL,网站的代码与位置无关,可以通过任何协议、域名、端口、子路径正常访问。本网站的代码甚至支持某些浏览器通过 FTP 协议浏览。如果想做镜像站,可以不用修改代码直接上传。
但是有些 URL,例如一些和 feed 相关的 URL 只能是绝对的。如果不确定生成的链接中哪些使用了绝对 URL,可以在生成的静态文件中全局搜索一下。
注:
- Pelican 的作者 Justin Mayer 不喜欢相对 URL。
- 如果 feed 中的图片使用了相对 URL,在 NewsBlur 中无法显示。因此,根据 Pelican 官方文档,建议所有图片都使用
语法,生成的图片 URL 在 HTML 中是相对的,在 feed 中则是绝对的。
文件名、目录结构和 URL 路径¶
在写博客时,需要在每篇博客头部设定一个独一无二的 slug 属性,作为文章的唯一标识符。slug 属性将会拼接到文章的 URL 中,因此最好一次性把它设置好,公开发布后,不要轻易更改。建议用英文、数字、连字符起一个简短而且能代表文章主题的 slug。建议不要让程序根据标题自动生成 slug,不要使用 hash 作为 slug,也不要在 slug 中使用中文。个人不太推荐把它设置为递增的数字编号。
洒家从一开始就没有修改 Pelican 和文章路径有关的默认设置,文章文件和 index.html、tags.html 等索引文件一起保存在网站根目录下。如果能重来,我会选择把文章放到类似 /posts/slug.html 或者 /posts/2020/1/slug.html 的位置,这样逻辑上更清晰,而且易于管理。
目录结构这种东西一旦规划好,有了读者,就不太容易修改。一旦修改,别的网站的外链就会 404,feed 也会刷屏。因此这个博客已经积重难返,考虑到文章放在根目录问题也不大,洒家选择保持现状。也许哪天我决定要改用独立域名,或者 GitHub Pages 停止服务了,迁移网站时再解决这个小问题。
2022 年 11 月注:洒家最近改变了 GitHub Pages 的部署方式,顺便把这个问题一起解决了。洒家把所有文章从 /slug.html 移动到了 /posts/slug.html,然后在 /404.html 里加了个跳转表,访问旧 URL 也可以自动跳转到新 URL。
全文 feed vs. 摘要 feed¶
这 2 种设置各有特点,选择哪一种是一个见仁见智的问题。大致来说,全文 feed 对读者更有利,摘要 feed 对博主更有利。
全文 feed 的特点:
- 优点:对读者比较方便,可以直接阅读全文,在离线情况下不用额外加载在线资源
- 缺点:Feed 不一定能能达到网页的显示效果(例如代码高亮)
- 缺点:给恶意采集爬虫略微降低了难度
摘要 feed 的特点:
- 优点:对博主有好处,向源站引流,可以增加流量、广告展示和点击量、用户反馈和评论,方便统计
- 优点:方便一些只读摘要的读者
- 缺点:对读者不方便
从博主的角度看,一般一个博客的主要流量来源是网页搜索,订阅的都是少数铁杆粉丝,使用全文 feed 对流量并没有太大影响。从读者的角度看,很多用户使用 feed 的目的都是希望在同一个地方聚合不同来源的信息,不希望再打开别的页面。洒家认为应该善待粉丝,使用全文 feed。
这里面的一些问题也可以被 feed 阅读器弥补。有信息聚合、离线阅读需求的用户可以设置阅读器提前自动爬取全文,只看摘要的读者也可以把阅读器设置为摘要显示模式。当然,这些就不是这里讨论的重点了。
扩展阅读:WordPress RSS Feeds: Summary vs. Full Text or Custom?(这篇文章中的“Custom RSS Feed”仍然属于摘要 feed)
WebSub(PubSubHubbub)¶
传统的 feed 阅读器使用轮询来更新订阅源。如果你不经常发文章,轮询的时间间隔会变得比较长,文章更新就会不及时,可能长达几小时甚至一两天。阮一峰每周五会发布一期周刊,假如订阅的读者周六才能看到,这肯定是不可接受的。
WebSub 协议可以解决这个问题。它是 Atom 和 RSS feed 的一套扩展协议,旧称 PubSubHubbub(真的会乱起名字)。有了它,就可以用 WebHook 主动推送代替轮询,实现 feed 阅读器中订阅源的秒级实时更新。协议的简介和细节可以查看 PubSubHubbub 协议详解和 W3C Recommendation - WebSub。
抛开协议细节,博主(Publisher)实际上只需要做 2 件事。第一,给 Atom/RSS XML 文件的根节点加一个子节点:
<link href="https://pubsubhubbub.appspot.com/" rel="hub"/>
洒家给 Pelican 写了个 plugin 实现了这一点。Feed 阅读器(Subscriber)看到这个 <link> 标签后,就会向指定的 Hub 发送一个包含回调 URL 的订阅请求。
第二,当博主发布了新文章,feed 文件(Topic)更新之后,需要向 Hub 发送一个简单的请求。这一步可以写脚本,也可以直接用 Google Hub 的网页工具操作,把 Atom/RSS XML 文件的 URL 粘贴到 Topic URL 输入框中提交即可。Hub 收到请求,知道了 Topic 有更新,就会通过请求回调 URL 向所有 Subscriber 发出通知。
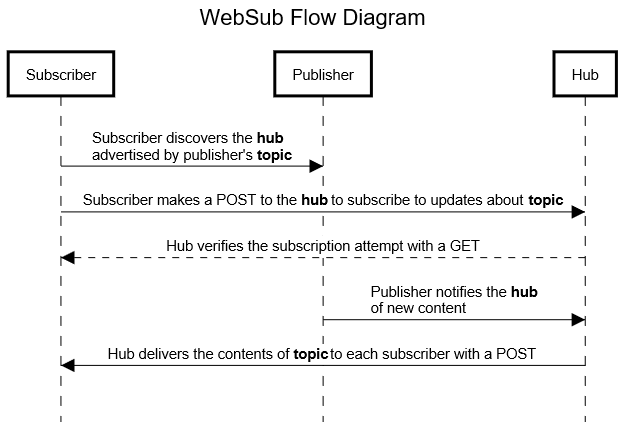
在 Inoreader 中可以看到,支持 WebSub 的订阅源的更新周期都显示为“实时”。博主 publish 后,抓取记录中会有一条图标为向下箭头的“发向 Inoreader 的推送请求”记录,同时几秒钟之内就能显示新文章。
阮一峰使用的 feed burner 和 WordPress.com 都支持 WebSub。
渲染 feed XML 文件¶
如果你不想让读者打开 feed 链接后看到一堆莫名其妙的 XML 代码,可以在 feed XML 文件中使用 XSLT,把 XML 渲染成 HTML。一个常见的例子是 FeedBurner,这个页面看起来是一个普通的网页,实际上 Content-Type 响应头为 text/xml; charset=UTF-8。
具体操作可以查看这篇文章:How to style RSS feed。
是否应该让链接默认在新标签页中打开?¶
洒家喜欢用浏览器的多标签页功能管理一个“浏览过程栈”,希望让链接默认在新标签页打开。于是洒家写了个 Python-Markdown 的扩展 markdown_link_attr_modifier,可以给 <a> 标签添加 target="_blank"、referrerpolicy="no-referrer" 和 rel="noopener noreferrer" 等属性。其中,设置 referrer policy 是为了保护隐私,设置 noopener 是为了防止 opener 劫持。
后来,洒家发现了 When to use target="_blank" 这篇文章,越琢磨越觉得有道理。默认在新标签页中打开链接改变了浏览器的默认行为,破坏了链接的行为一致性。当用户来到一个陌生的网站,如果想在新标签页中打开链接,一定会习惯性地右击链接然后单击“在新标签页中打开链接”,或者鼠标中键点击链接,或者 Ctrl/Command + 单击打开链接,而不会直接单击链接。如果用户想在当前页面打开链接,直接单击链接却打开了新标签页,就会感到小小的意外,然后还是会关闭老标签页。因此,加上 target="_blank" 属性并没有什么意义,连我自己都想不起来用,而且还会对用户体验起到反作用,也就只能让不知道自己在干嘛的小白在网站上多停留几分钟而已。因此,洒家又把链接的 target="_blank" 属性删掉了。
链接的默认行为不是网站的事,而是用户的事。如果用户想让所有链接都在新标签页中打开,可以想办法修改浏览器的全局设置,这样无论是哪个链接,都可以放心地用左键单击,所有链接的行为都是一致的。
链接的 title 属性¶
在添加链接时,如果链接文字太简略,洒家会花几秒钟时间加上 title 属性,写上关于链接目标的简单的说明。示例 Markdown 代码及其渲染结果如下,把鼠标指针放到渲染结果的链接上即可看到效果。
[这篇文章](https://www.ruanyifeng.com/blog/2021/01/_xor.html "阮一峰的网络日志:异或运算 XOR 教程")里有异或运算的基础知识。
这篇文章里有异或运算的基础知识。
一些目标不言自明的链接则不用专门加 title 属性。为了保持一致,防止读者疑惑有的链接有提示有的却没有,洒家也会用上文提到的 markdown_link_attr_modifier 扩展自动给没有 title 属性的链接添加 title 属性。
中西文混排¶
为了美观,中西文混排时,应当在交界处加上空格。具体规则是:使用半角方式输入西文(英文字母、数字等),在中西文交界处插入一个半角空格,但是西文和任何中文全角标点符号交界处不需要加入半角空格。
- 正确示例:这个 SSD(固态硬盘)的价格是 20 元。
- 错误示例:这个SSD (固态硬盘)的价格是20元。
更详细的规则可以阅读这篇中文文案排版指北。一般来说,网页、纯文本都需要遵守此规则,除非使用高级的排版软件,例如 Word 默认会增大中文和西文的间距。
洒家自己写了个脚本来分析 Pelican 生成的 HTML 文件。首先提取想要的 HTML element,去掉所有 tag,然后检查每一行是否符合此规则,不符合规则的可以突出显示。
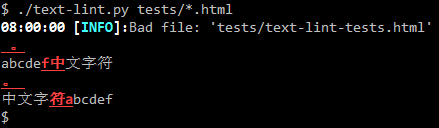
下面是一些其他的解决方案,洒家没有用过,记录在这里供读者参考:
语言风格¶
洒家尽可能使用现代通用的标准汉语和规范汉字,尽可能准确表达,避免歧义。尽量避免中英夹杂、中文西化等现象,不用网络流行语、emoji(抽象话)、意义不明的拼音首字母缩写等。相比于会长期存在的博客文章,网络流行语就是一阵风,几年之后不火了,读者都读不懂了,自己看到都会觉得尴尬。

如果使用了读者可能不了解的网络流行语和专业术语,洒家会给它们加上萌娘百科、维基百科链接。同理,当提到别的网站或网页时,洒家也会加上链接。
扩展阅读:
- 怎样改进英式中文?- 论中文的常态与变态,作者为余光中,原文刊于《明报月刊》1987 年 10 月号
安全和隐私¶
洒家是搞信息安全的,比较重视隐私保护;以前经常做 CTF Misc 隐写取证题,也知道点隐藏信息的套路。下面是一些关于安全和隐私的小细节。
HTTPS¶
现在都已经 2021 年了,网站早就应该设置为默认强制 HTTPS 访问了。一个 HTTP 的网站会显得很不专业。
- 自建服务器:可以使用 Let's Encrypt 自动获取免费证书,最好再加上 HSTS 响应头。
- GitHub Pages:勾上
Enforce HTTPS选项即可。 - Cloudflare:网页控制台里可以设置的项目很多,建议一步到位,把
SSL/TLS encryption mode设置到Full (strict)等级(所有连接都加密并校验证书),Origin Certificates和Authenticated Origin Pulls都配置好,Minimum TLS Version根据当前的技术发展情况调高一点(2021 年应至少设置为TLS 1.2),再把HTTP Strict Transport Security (HSTS)打开。
配置完毕后,最好再用 Qualys SSL Labs 出的 SSL Server Test 这种在线工具检测一下配置有没有遗漏之处。
图片¶
- 终端的背景应该设置为不透明的纯色,防止截图时把窗口后面的东西截下来。
- 有的页面含有肉眼不可见的盲水印,截图时会泄露个人身份信息,防不胜防。2016 年阿里巴巴内部抢月饼事件就是一个典型案例。如果都对抗到这种程度了,他们不想让你擅自向外传输信息,建议就别搞事情了。如果一定要搞事情,可以用手机稍微模糊地拍下来,或者把文字手动打出来。如果一定要截图,可以先二值化,然后放大图片仔细观察有没有不明黑点和白点,字体线条有没有毛刺。然后可以把腐蚀、膨胀、开运算、闭运算、模糊、锐化全招呼上。另外不要对可以感知自己被截图的 APP 截图,哪个用户截了图都可以直接查出来。
- 插入图片时,要检查图片中包含的敏感信息,打上马赛克。马赛克不能太薄,可以先涂抹一下或者加点噪声,然后再打马赛克,否则仍然可能被识别。
- 插入图片时,要检查并清除图片的 Exif 信息。
- 微信支付、支付宝打赏二维码可能泄露真实身份。
链接¶
现代的 URL 中经常会加入用于跟踪和统计的参数,其中可能包含个人账号的身份识别信息。插入链接时,要把 URL 中的这些参数清理干净,尽量删除到最短。以网易云音乐客户端为例,假设有人点击分享 - 复制链接,得到的 URL 是 https://music.163.com/song?id=114295&userid=198554。其中 id 参数的值 114295 是音乐的 ID,而 userid 参数的值 198554 则是分享者的 ID,我们就可以顺腾摸瓜找到分享者的主页:https://music.163.com/#/user/home?id=198554。
扩展阅读:
Feed、网页存档与被遗忘权¶
- Feed 阅读器具有自动存档的作用。一旦 Feed 被抓取,文章被收录,原始版本可能会被永久保存,后续修改或删除可能不会被同步更新(例如 Feedly、Inoreader)。这也意味着即使网站关闭了,在 Feed 阅读器里输入 Feed 源 URL 还是能看到网站的内容。
- 网页存档服务同理。常用的网页存档服务有 archive.org 的 Wayback Machine,以及 archive.today 等。
这可能侵犯了人们的被遗忘权。但是,在目前的形势下,不因为来自不可抗力的一句话就被遗忘的权利似乎比被遗忘权更应该首先得到保护。如果无法自由选择是否被遗忘,那么我们可以被迫选择牺牲被遗忘权。洒家的浏览器里安装了存档扩展程序,也已经培养出了敏锐的嗅觉。如果察觉到网页有可能被消失,就会毫不犹豫地存档。
事实上,无论怎么努力,我们都只能提高考古的难度,却无法彻底被遗忘,让信息彻底消失。信息一旦公开就如同倒在地上的水一样不受控制,难以收回,甚至可以永存。毕竟我们无法阻止读者保存网页,或者截图拍照。因此,在点击发布按钮时要慎重,不要公开发表未来的黑历史。
此外,Feed 阅读器还有其他值得注意的地方:
- NewsBlur 会为添加到该平台的每一个订阅源分配一个可遍历的 ID,例如 https://www.newsblur.com/site/23644/。随便改个数字,就可以拿到其他订阅源的 URL 和内容。因此最好不要用公共 feed 服务订阅和发布私密的内容。
扩展阅读:
- How to Remove Your Website From The Internet Archive (2020)
- Archive.is blog: How can I delete an archived page?
总结¶
说了这么多,洒家并不是极端隐私保护主义者,也不是极端受迫害妄想症。我们在互联网上的身份是虚拟的,只是不希望这个虚拟身份和真实身份之间之间的关联发生失控,反之,主动可控地透露自己的真实信息则是可以接受的。所以,这些细节主要是为了防止在意料之外泄露信息,需要结合自己的实际情况来考虑,可能并不需要每条都遵守。如果你从一开始就计划实名写博客,姓名、邮箱、工作单位等个人信息本来都是公开的,文章中再出现姓名当然就不算泄露了。
扩展阅读:
- 恶俗狗维基:概念/出道,包含人肉搜索的常用方法及其应对措施
SEO¶
洒家目前只是佛系 SEO,简单玩一玩,主要还是为了体验过程。
首先,把 robots.txt、sitemap.xml、feed 全都安排上。由于 robots.txt 基本不会变化,直接用静态文件即可,记得在里面加上 Sitemap 指令。sitemap.xml 则使用 Pelican 的 plugin sitemap 动态生成。每次生成静态文件时,这个 plugin 都会更新 sitemap.xml 文件中 indexes 类型 URL 的 <lastmod> 属性。除非此文件有实质性更新,洒家一般都会在提交时忽略此文件的更改,这样可以减少无意义的提交,而且据说原本也不应该频繁更新和提交 Sitemap。
上文提到,洒家使用了 Google Search Console,针对性的 SEO 也是以 Google 为主。(不会有搞计算机的上不了 Google 吧?不会吧?不会吧?)其他搜索引擎如果提供了可以直接匿名提交网址或者 Sitemap 的接口,就在有更新的时候提交一下,反之如果必须实名认证注册站长平台,那就算了。
一些可以快捷提交网址的服务:
- 向 Google 匿名提交 Sitemap:
https://www.google.com/ping?sitemap=<URL> - 向 Bing 匿名提交 Sitemap:
https://www.bing.com/ping?sitemap=<URL> - 向百度匿名提交博客地址或者 RSS:https://ping.baidu.com/ping.html(2021 年 1 月注:这个服务似乎已经关闭)
- 向百度提交链接:https://ziyuan.baidu.com/linksubmit/url(需要登录百度账号)
据说前几年由于一些原因,GitHub 屏蔽了百度搜索引擎的爬虫,有的贴子显示 2019 年 2 月 GitHub 响应都是 403 Forbidden。但是洒家使用百度搜索 site:phuker.github.io 并查看百度快照,发现起码 2020 年百度可以收录本站内容,只是收录不全而且更新频率很低。
这里正好提到了百度,洒家想吐槽两句。我建议小站站长就别折腾百度了,它连爬都懒得爬你。就算爬了,收录也不全。就算收录了,不管你的搜索关键词写得多精准,你的网页排名也在几十页之后。排在前面的是什么呢?是和搜索关键词八竿子打不着的 CSDN,甚至还可能是原文抄袭你的文章的采集站。
全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。
上面这两句百度的介绍,可以说连标点符号都是槽点满满。
百度就是个垃圾。
洒家建议有能力的用户使用 Google。如果你想自己折腾一波,再推荐一下我写的 Searchit。这是一个元搜索引擎,可以同时搜索百度和 Google。一些老网民可能还记得,曾经有一个叫“百 Google 度”的网站。后来上头不让搞,这个站倒闭了,我就自己写了一套高仿的,自己搭服务自己用。以我使用这种网站接近 10 年的经验,即使搜索中文关键词,八九成的时间点击的也是右边 Google 的链接。
洒家暂时不想深入分析造成这一切的原因,最后就推荐几篇相关的文章吧。
- “作环保的程序员,从不用百度开始”,陈皓,2013-3-23
- 和百度说再见——中文搜索引擎推荐,idealclover,2020-2-28
- 搜索已死,谁来烧纸。,曹政,2019-07-26
- 当互联网不再互联,idealclover,2020-3-10
扩展阅读¶
- 告别删文:在哪里写博客?,王玄的博客,2020-3-4
- 为什么我不在微信公众号上写文章,陈皓,2016-7-11
- 维基百科:更优秀条目写作指南,包含编辑维基百科时排版和内容等方面的建议,很多也适用于博客
- 中文独立博客列表
-
个人网站不像商业产品,不用无限增加冗余功能满足 KPI,什么火就往 APP 里加什么,连完美的极限都不存在。现在你可以在几乎任何一个国产 APP 里贷到款,无论它是聊天软件,打车软件,外卖软件还是直播软件。↩

